

Deploy AI Models with RabbitMQ Message Broker
In simple steps with Flask and RabbitMQ as Message Broker


Table of contents
⚠ Disclaimer
This blog is focused on the situation when you need to handle a low number of users to access your AI models, like in a hackathon or a prototype of a product which may not be accessed by more than 500s people concurrently. More optimization and robust design are required for production usage. But this blog can be a good starting point.
🏊 Let's discuss the problem with Client-Server architecture.
We all know maximum AI models are resource-hungry operations and take at least from 1 second to up to 5 minutes, especially for large deep learning models.
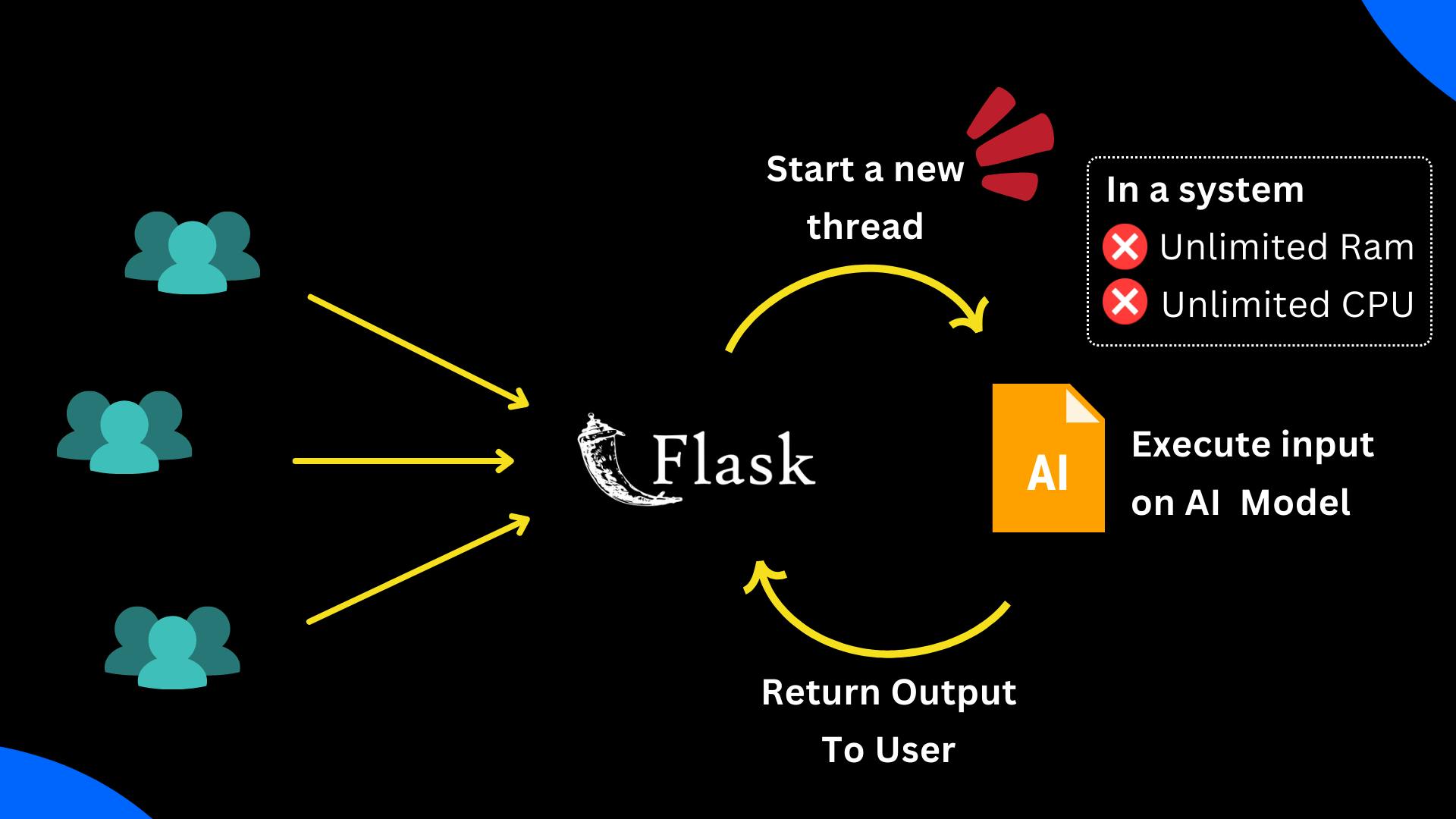
The main problem is that we can't run too many requests in a low-end system (2GB RAM, 2vCPUs).
As we have 2 CPU cores, running more than two threads is impossible. As a result, the system crashed.
If the processing time of the model exceeds Nginx/web gateway timeout, it will give the user an error and waste the system's resources.
🏂 Now, What's our approach?
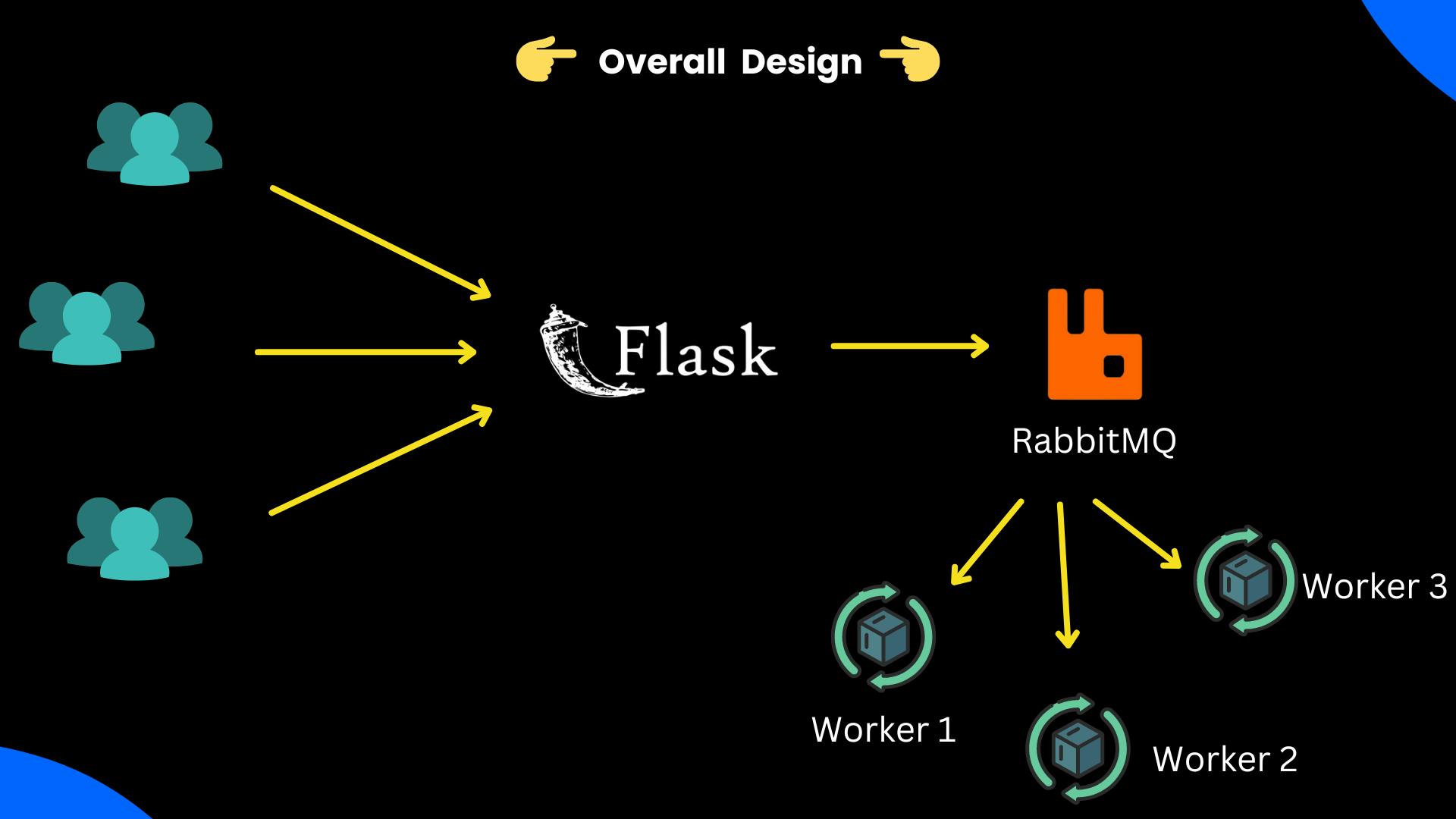
We will take the microservice approach and split our system into three parts. So that user can get a message asap about the request received by the server and later can enquire about the result.
Flask Web Server
RabbitMQ as message broker and queue management [It comes as packaged software. We will use a cloud-based free one. I will discuss this in a later part]
Worker process - will be responsible for running the input data on AI models.
Let's understand the overall architecture of the system by ⏬
Before going into more depth, let's know the process in short
The user will send the request to the server
The server will create an entry in a table with status processing
The server then sends the input and request ID to the RabbitMQ message broker
The worker process will receive the request ID and input. It will run the AI model and generate the output based on the received input.
Then the worker process will submit the result to the server and mark the request-id status as done.
During this, the end-user can request the server for its result. If the result is available to the server, the end-user will get the result else; the end-user will resend the request in a while.
👀 Detailed Concept
We will first clarify how this will work and solve our issue of limited resources. Then we will move to code.
1️⃣ Process New Request Coming From End-user
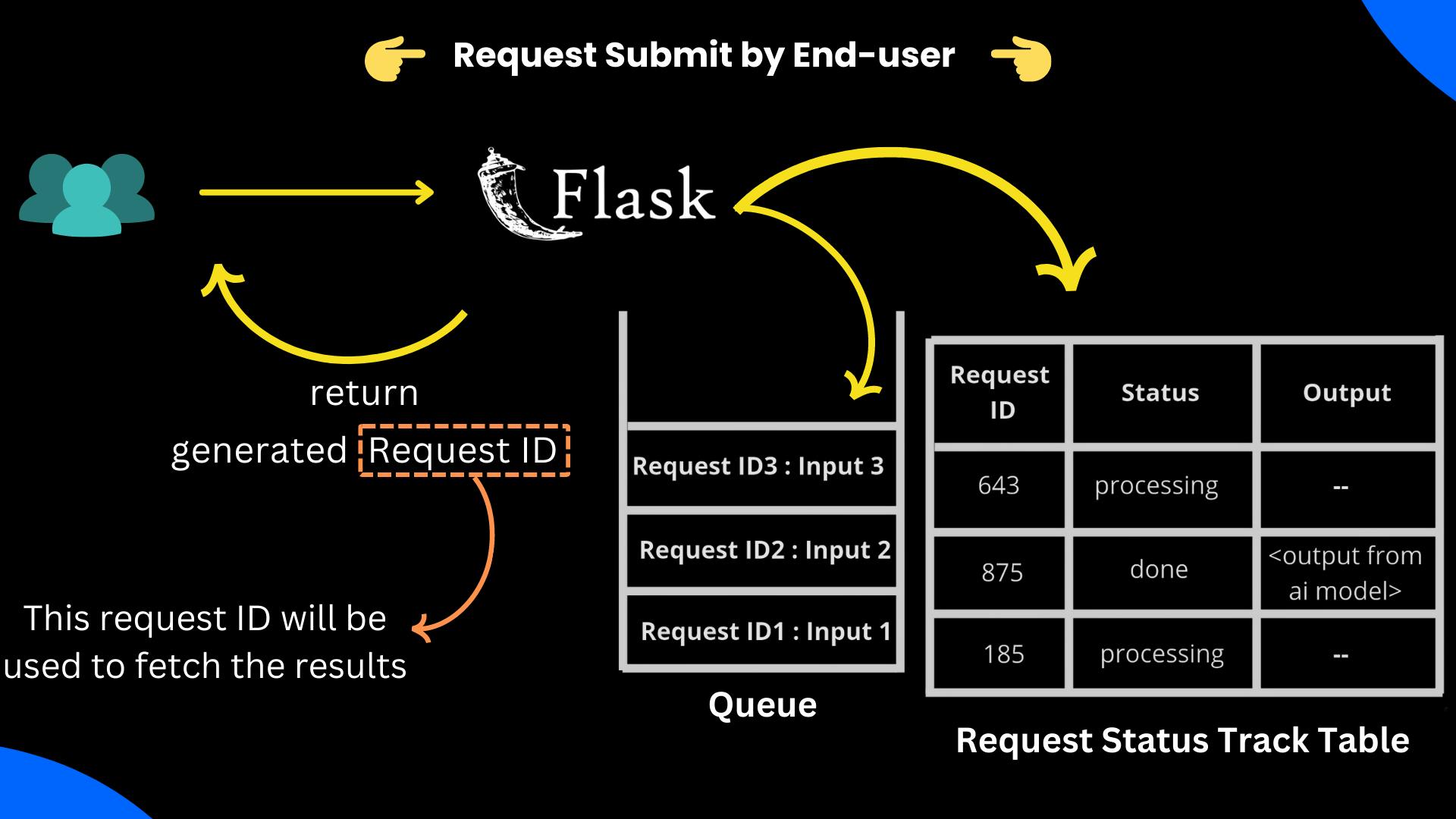
As soon as the request is received, the backend will do three tasks one by one
Make an entry in the Request Status Track Table to keep track of request
Push the request details <Request ID, Input> to the queue
Send an acknowledgement message to the user that the request is processing. Also, send the Request ID with the response so that the user can enquire about the result later
2️⃣ Consumer/Worker: Pop Process From Queue and Process It
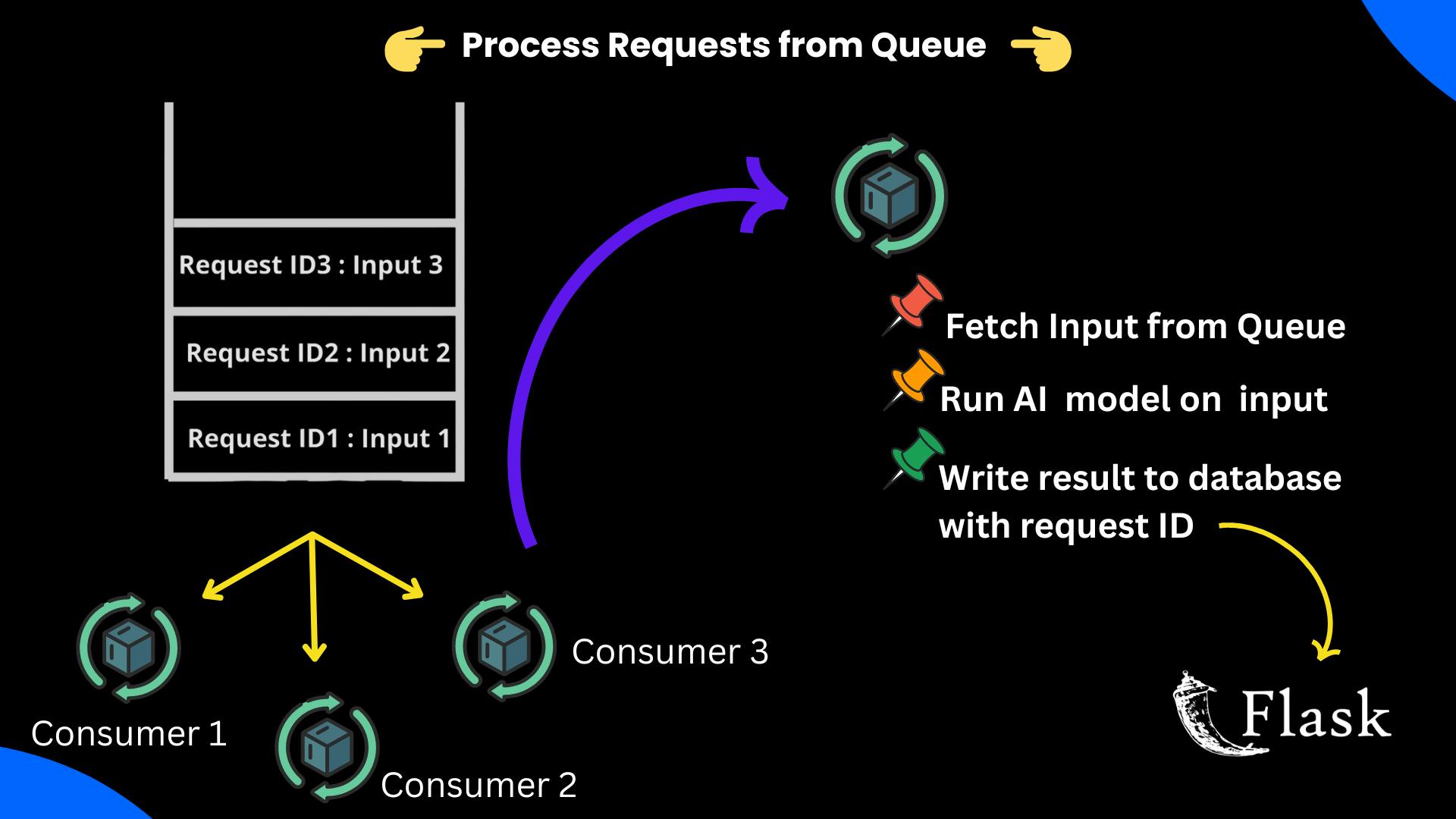
The consumer/worker listens for new requests, and RabbitMQ is responsible for giving the task to its listeners. It will follow the following steps.
The worker will extract the Request ID and Input it from the received payload.
The worker will run the input to the AI Modal and prepare the output.
Then the worker will update the output and status to done by specifying the request ID. Now, this can be done in two ways -
Connect to the database directly
Call API of the backend [Recommended]
3️⃣ Fetch Result of Request by the End-user
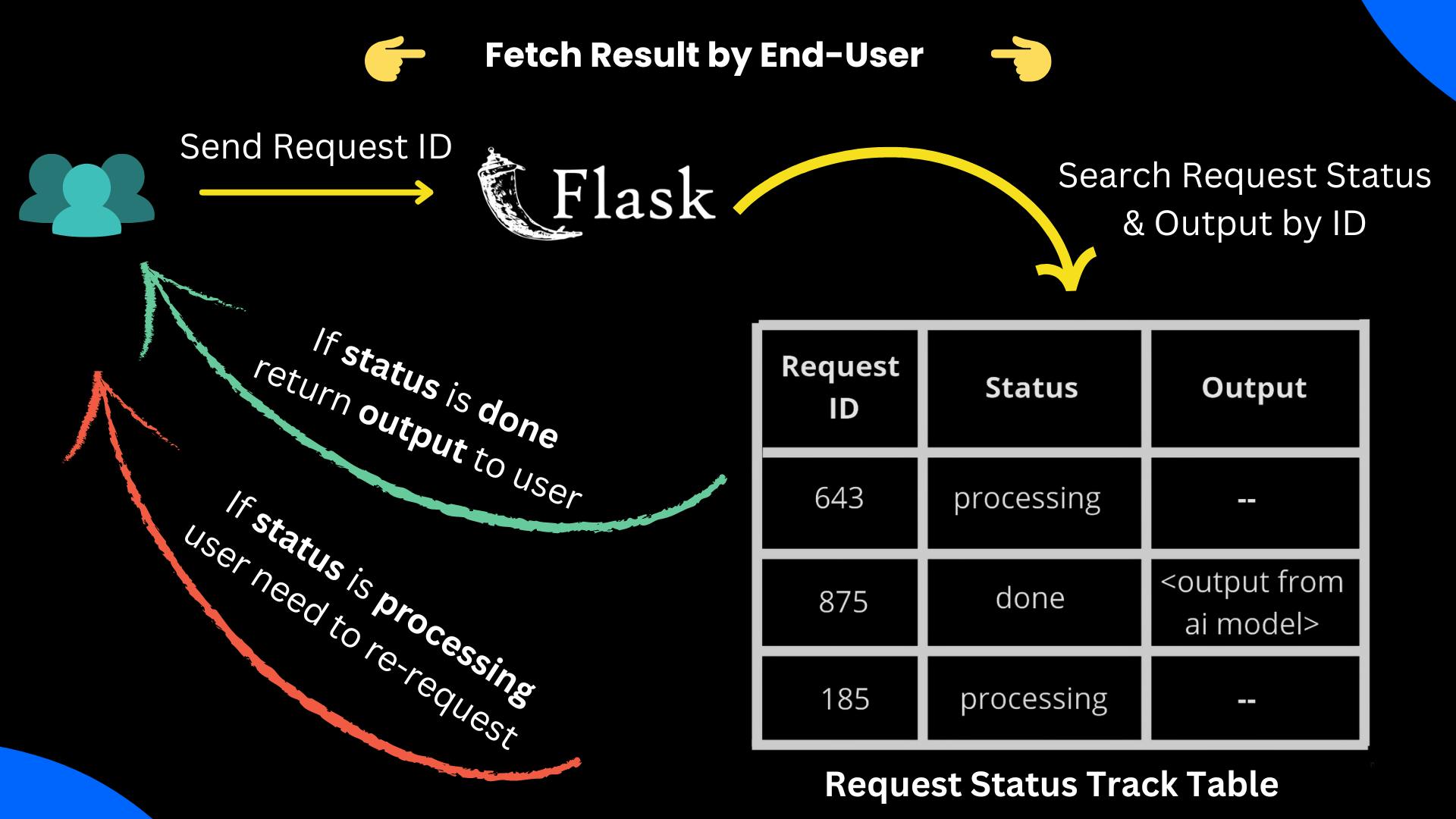
After a fixed interval(for example, 5 sec), the end-user will request the backend to send the result of his query.
Now the process flow of the backend will be
It will check the status of the request by its ID.
If the status is still processing, the backend will tell the end-user about its status and will say to them to re-request later.
If the status is done, the backend will send the output to the end user.
That's all !
💻 It's Coding Time
⚠ Read This Note Before Approaching Coding Part
Using an actual AI model's code will complicate this writing. We prefer to simulate that by a long-run function.
As an example, we will calculate the factorial of a large number.
def calculate_factorial(n):
result = 1
if n > 1:
for i in range(1, n+1):
result = result * i
return result
For factorial(n), n > 150000, it takes more than 10 seconds to compute

It's perfect for our use case.
🕰 Current Backend In Flask
from flask import Flask, request
# Function to calculate the factorial of a number
def calculate_factorial(n):
result = 1
if n > 1:
for i in range(1, n+1):
result = result * i
return result
# create the Flask app
app = Flask(__name__)
# route to calculate the factorial of a number
@app.route('/factorial', methods=['GET'])
def factorial_handler():
no = int(request.args.get('no'))
result = calculate_factorial(no)
return str(result)
if __name__ == '__main__':
app.run(debug=False)
Try to run the 5~6 requests at a time and see what happened
curl http://127.0.0.1:5000/factorial?no=150000
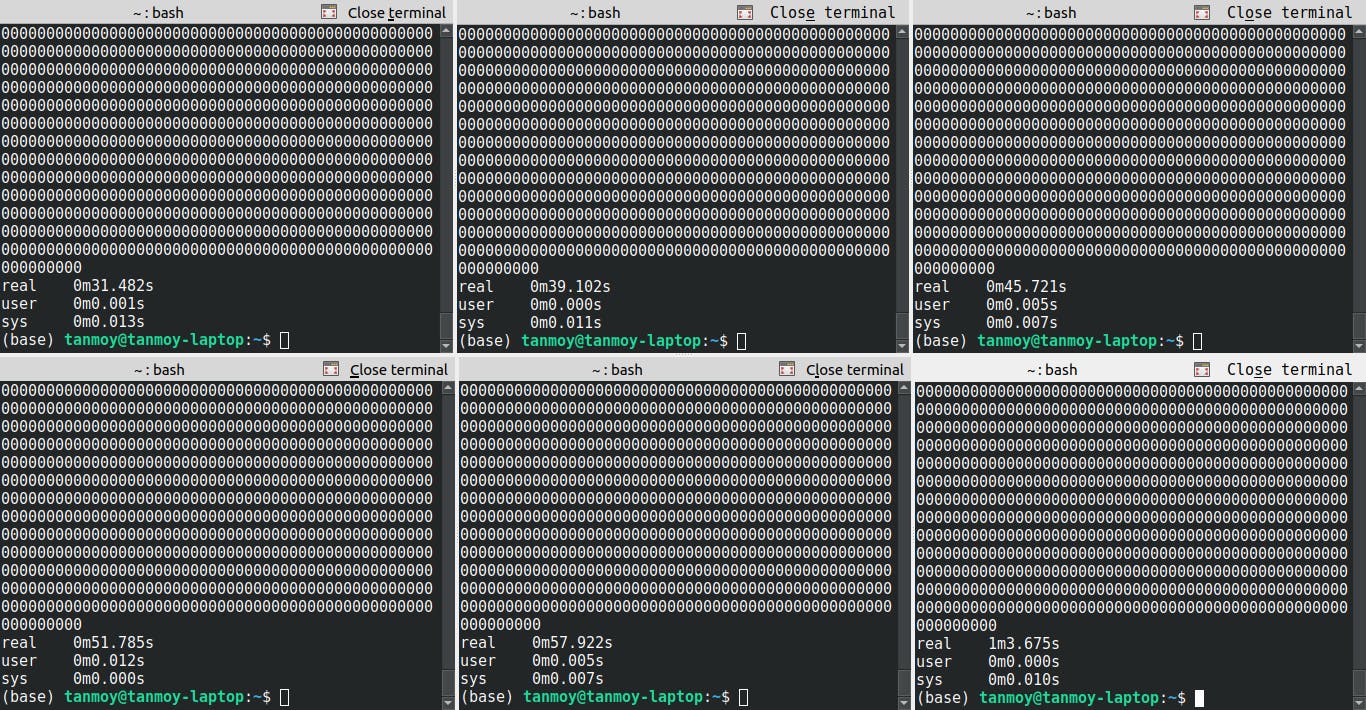
See, the last request takes more than 1 minute 💣💣.
As the processing time of the function increases, the waiting time per user will increase exponentially.
⏰ Time To Rebuild Our Backend
🟠 First, create a cloud-hosted RabbitMQ service
Go to https://www.cloudamqp.com/ and create a free account
Create a free RabbitMQ instance
Click on the name of the instance
Copy the URL from AMQP details.
🟡 Run An Redis Instance Locally
You can follow the guide to install Redis in your system. https://redis.io/docs/getting-started/installation/
Run the Redis server locally by running this command
redis-server
🟢 Prepare the helper functions beforehand
We need to create some functions -
| Function | Definition |
| publish_to_rabbitMQ(data) | It will publish the data to rabbitMQ |
| create_request(input) | Create a request entry in Redis, do an entry in RabbitMQ and return the ID of the request |
| get_request(request_id) | It will fetch the request details by the id from Redis |
| update_request(request_id, status, output) | It will update the status and output of the request in Redis |
Implementation of publish_to_rabbitMQ(data):
import json
import pika
def publish_to_rabbitMQ(data):
# Create connection
connection = pika.BlockingConnection(pika.URLParameters("amqps://yyyyyy:xxxxxxxxx@puffin.rmq2.cloudamqp.com/yyyyyy"))
channel = connection.channel()
# Create queue . For now queue name is factorial_process
channel.queue_declare(queue='factorial_process', durable=True)
# Publish the message to the queue
channel.basic_publish(exchange='', routing_key='factorial_process', body=json.dumps(data))
# Close the connection
connection.close()
Implementation of create_request(input) :
def create_request(input):
# Generate a random ID
random_id = str(uuid.uuid4())
# Store the request in Redis
redis_instnace.set(random_id, json.dumps({'input': input, 'status': 'processing', 'output': ''}))
# Publish the request to RabbitMQ
publish_to_rabbitMQ({'request_id': random_id, 'input': input})
# Return the request ID
return random_id
Implementation of get_request(request_id) :
def get_request(request_id):
request_data = redis_instnace.get(request_id)
if request_data:
return json.loads(request_data)
return None
Implementation of update_request(request_id, status, output):
def update_request(request_id, status, output):
request_details = get_request(request_id)
redis_instnace.set(request_id, json.dumps({'input': request_details['input'], 'status': status, 'output': output}))
🔵 Re-design Flask Backend
We will remove the processing part from it
Create two more APIs
/factorial/result?id=random: To fetch the results of the request
/factorial/update: To update the result and status of the request
from flask import Flask, request
from helpers import create_request, get_request, update_request
# create the Flask app
app = Flask(__name__)
# route to queue the request
@app.route('/factorial', methods=['GET'])
def factorial_handler():
no = int(request.args.get('no'))
id = create_request(no)
return id
# route to get the result
@app.route('/factorial/result', methods=['GET'])
def factorial_result_handler():
id = request.args.get('id')
result = get_request(id)
return result
# route to update the result
@app.route('/factorial/update', methods=['POST'])
def factorial_update_handler():
body = request.get_json()
id = body['id']
status = body['status']
output = body['output']
update_request(id, status, output)
return 'OK'
if __name__ == '__main__':
app.run(debug=False)
⚪️ Build The Consumer
import pika
import json
import requests
# Function to calculate the factorial of a number
def calculate_factorial(n):
result = 1
if n > 1:
for i in range(1, n+1):
result = result * i
return result
# Create a callback function
def callback(ch, method, properties, body):
body = json.loads(body)
request_id = body['request_id']
print('Received request with ID: ', request_id)
input = body['input']
output = calculate_factorial(input)
# Update the status to done
requests.post('http://localhost:5000/factorial/update', json={'id': request_id, 'status': 'done', 'output': output})
def start_consumer():
# Create connection
connection = pika.BlockingConnection(pika.URLParameters("amqps://yyyyyy:xxxxxxxxx@puffin.rmq2.cloudamqp.com/yyyyyy"))
channel = connection.channel()
# Create queue . For now queue name is factorial_process
channel.queue_declare(queue='factorial_process', durable=True)
# Listen to the queue and
# call the callback function on receiving a message
channel.basic_consume(queue='factorial_process', on_message_callback=callback, auto_ack=True)
# Start consuming
channel.start_consuming()
if __name__ == '__main__':
start_consumer()
📢 Let's see that in action
Let's send a request to the backend server.

That's our request id 748879f5-6504-4fbf-823a-74e6c44a3357

The consumer is running 🔥. We can also see the consumer has received the request bearing id 748879f5-6504-4fbf-823a-74e6c44a3357.

We queried the server with the id. But that is still processing.
-> After some time 🕓, we rerun the query. And this time, we got our results. The result is too long to show here. So truncated the output.
curl http://127.0.0.1:5000/factorial/result?id=748879f5-6504-4fbf-823a-74e6c44a3357
> {"input": 150000, "output":"....truncated", "status": "done"}
🚀🚀 Congratulations. That's all.
You can spin many consumers to make the resulting process much faster.
Not only AI model, but you can also build many things based on this concept of microservice architecture.
Whatever, with this design, when your userbase grows results may come a bit late but your backend will not be unresponsive. To make it faster you can spin more consumers.
⚡Some Optimization Tips
The polling method is acceptable but is not suitable for large users. We can use WebSocket in place of polling to reduce network calls.
We should consider deleting the processed request records from the database as they have no use.
We can also consider using an in-memory database like Redis to store the data of requests.
The endpoints must be secured so the internal consumer/worker can access them.
Make the consumer/worker dockerize so it can be easy to run multiple consumers using Amazon EKS, ECS, or other services.
If you liked this blog, share this blog and subscribe to the newsletter.